


出品 | 搜狐科技
作者 | 梁昌均
在DeepSeek-V3模型更新两个月后,DeepSeek-R1也迎来低调升级。
5月29日晚,DeepSeek在公众号正式发文披露DeepSeek-R1升级为DeepSeek-R1-0528,并发布官方测评。
此次更新后的新模型思考更深,推理更强,主流基准测评在国内所有模型中首屈一指,整体表现接近OpenAI的o3、谷歌的Gemini-2.5-Pro等国际顶尖模型。
前一天晚间,DeepSeek官方在用户交流群中宣布R1推理模型完成小版本试升级,29日凌晨则在开源社区公开了模型及权重,并陆续更新了模型卡等更多信息。
这次低调的更新在海内外开发者社区和社交平台仍引发不小关注。综合多位网友体验,DeepSeek-R1-0528在编程、逻辑推理、交互能力等方面均有显著提升。
“这个小升级实际上是一个重大的飞跃”,这是不少人的实测体验。随着DeepSeek-R1新模型登顶全球最强开源模型,网友们也纷纷发问:DeepSeek-R2,还有多远?
整体性能接近o3,幻觉率降低45%-50%
DeepSeek发布的测评结果显示,更新后的R1模型在数学、编程与通用逻辑等多个基准测评中取得了当前国内所有模型中首屈一指的优异成绩,并在整体表现上已接近其他国际顶尖模型,如o3与Gemini-2.5-Pro。
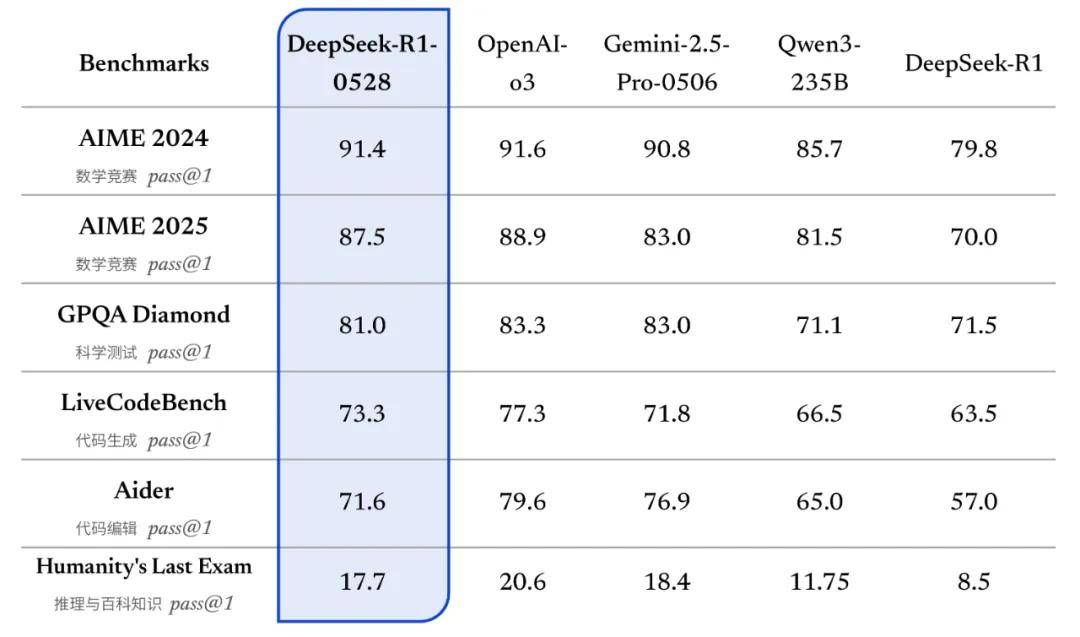
官方公布的测试显示,DeepSeek-R1-0528在数学竞赛、科学、代码生成和编辑,以及推理与百科知识等主流基准上的表现,相较DeepSeek-R1均有明显提升。
DeepSeek提到,相较于旧版R1,新版模型在复杂推理任务中的表现有了显著改进。如在数学测试AIME 2025中,准确率由70%提升至87.5%,这得益于模型在推理过程中的思维深度增强。
在该测试中,旧版模型平均每题使用12K tokens,而新版模型平均每题使用23K tokens,表明其在解题过程中进行了更为详尽和深入的思考。
更为重要的是,DeepSeek-R1-0528在这六大基准测试中均超过阿里的Qwen3-235B,数学和代码生成能力也超过谷歌Gemini-2.5-Pro-0506。但整体来看,该模型与o3相比仍还有微弱差距。
其它更新方面,新版DeepSeek-R1针对幻觉问题进行了优化。此前,在Vectara HHEM人工智能幻觉测试(通过检测语言模型生成内容是否与原始证据一致,从而评估模型的幻觉率)中,DeepSeek-R1幻觉率为14.3%,是DeepSeek-V3的近4倍,也远超行业平均水平。
与旧版相比,此次更新后的模型在改写润色、总结摘要、阅读理解等场景中,幻觉率降低45%-50%左右,能够有效地提供更为准确、可靠的结果。
在创意写作方面,更新后的R1模型针对议论文、小说、散文等文体进行了进一步优化,能够输出篇幅更长、结构内容更完整的长篇作品,同时呈现出更加贴近人类偏好的写作风格。
DeepSeek-R1-0528还支持工具调用(不支持在thinking中进行),其在Tau-Bench测评成绩为Airline 53.5% / Retail 63.9%,与OpenAI-o1-high相当,但与o3-High及Claude 4 Sonnet 仍有差距。
Tau-Bench是OpenAI董事会主席布雷特·泰勒(Bret Taylor)创办的公司Sierra推出的评估AI智能体在复杂现实任务中与用户和工具交互的能力,主要设计了Retail(零售场景)和Airline(航空场景)两个垂直领域的评测。
此外,新版R1 API仍支持查看模型思考过程,同时增加了Function Calling和JsonOutput的支持。Function Calling也就是函数调用,是一种允许AI模型在特定任务中调用预定义函数或API的机制,用于增强模型的处理能力和功能,是大模型与外部世界交互的关键技术。
OpenAI的GPT模型、百度文心模型等主流模型均支持Function Calling。这也意味着,DeepSeek-R1-0528模型将增强与外部工具交互的能力,有助于智能体应用开发。
DeepSeek还表示,DeepSeek-R1-0528在前端代码生成、角色扮演等领域的能力也均有更新和提升。
在代码能力方面,代码测试平台Live CodeBench显示,在最近一年内的模型评测中,DeepSeek-R1-0528性能仅次于OpenAI在4月发布的o4 mini和o3-high版本。
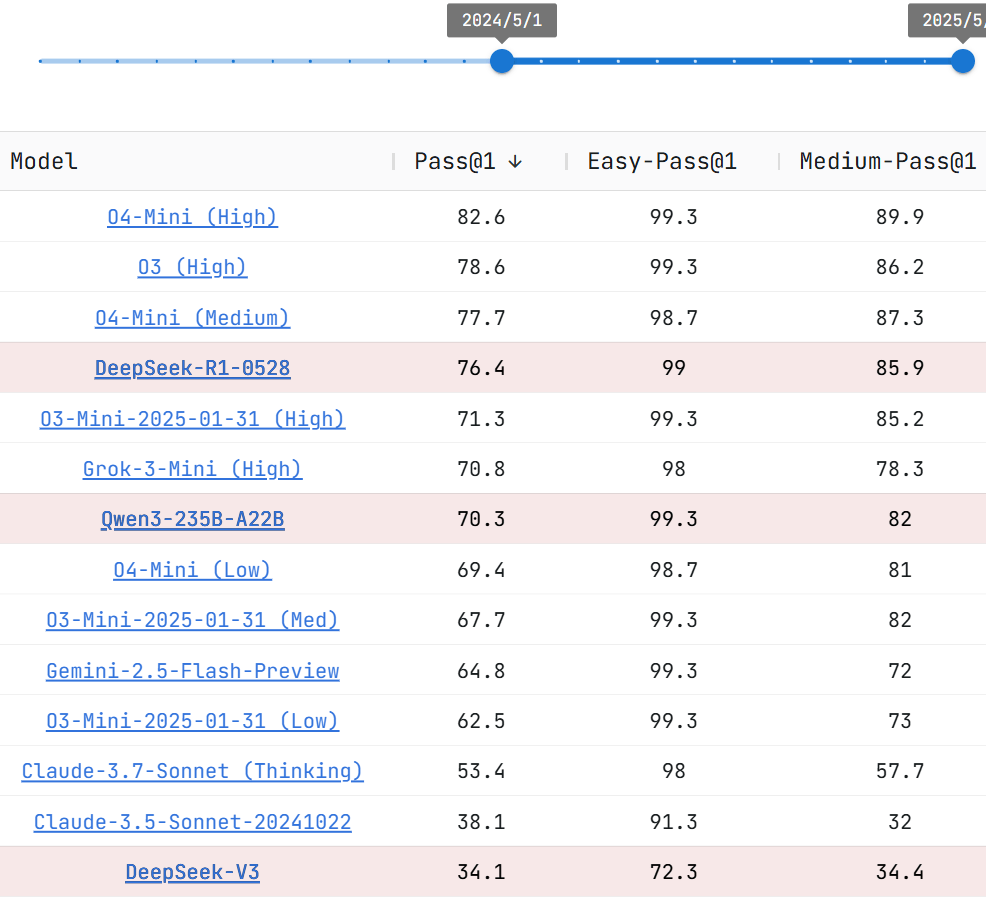
在模型上下文长度方面,R1新模型在官方网站、小程序、App端和API中的模型上下文长度仍为64K。如果用户对更长的上下文长度有需求,可以通过其他第三方平台调用上下文长度为128K的开源版本R1-0528模型。
DeepSeek还对DeepSeek-R1-0528进行了蒸馏,通过蒸馏该模型的思维链后训练Qwen3-8B Base,得到了DeepSeek-R1-0528-Qwen3-8B,且仍具备比较强大的推理能力。
比如,该模型在数学测试AIME 2024中的表现仅次于DeepSeek-R1-0528,阿里超过的Qwen3-8B和Qwen3-32B,以及微软的Phi-4-14B等模型,与参数更大的Qwen3-235B相当。

“我们相信,DeepSeek-R1-0528的思维链对于学术界推理模型的研究和工业界针对小模型的开发都将具有重要意义。”DeepSeek表示。
目前,该模型目前已在魔搭社区和HuggingFace开源,沿用宽松的MIT License 许可,DeepSeek-R1系列(包括Base和Chat)都支持商业使用和蒸馏。
“这是开源的又一次巨大胜利”,“开源的另一个里程碑”,有开发者评论到。
DeepSeek行业地位和谷歌拉平,重回全球开源巅峰
虽然DeepSeek官方称这次是小版本升级,但依然在国内外社区引发不小关注。
专注于AI基准测试和分析的独立平台Artificial Analysis发文表示,DeepSeek最新模型超越xAI、Meta和Anthropic,与谷歌并列成为世界第二领先的AI实验室,并成为无可争议的开源领导者。
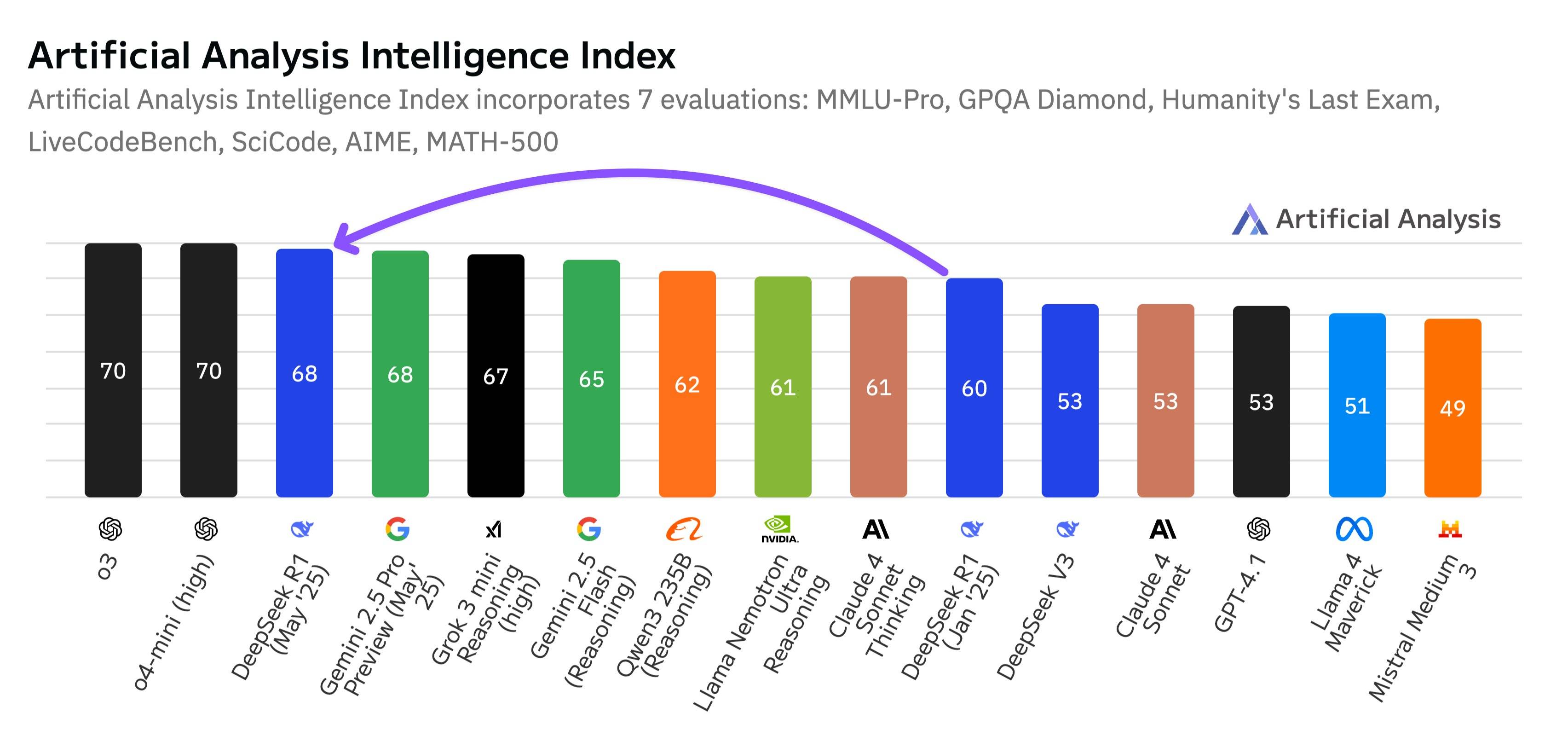
该机构称,DeepSeek-R1-0528在Intelligence Index(涵盖通用能力、数学、科学、代码等七项主流基准测试)中的得分从60跃升至68,这一增长幅度与OpenAI的o1到o3(从62到70)的提升相当。
根据该机构发布的最新排名,DeepSeek-R1-0528综合智能水平超过了Anthropic的Claude4-Sonnet、阿里的Qwen 3-253B、谷歌Gemini 2.5 Flash、xAI的Grok 3 mini (high)等推理模型,与谷歌Gemini 2.5 Pro持平,与OpenAI的o3和o4-mini(high)仅有两分之差,夺回全球最强开源模型的地位。
过去几年,全球最领先的模型在OpenAI、Gemini、Grok等模型中轮换,有网友称现在又轮到了DeepSeek了。

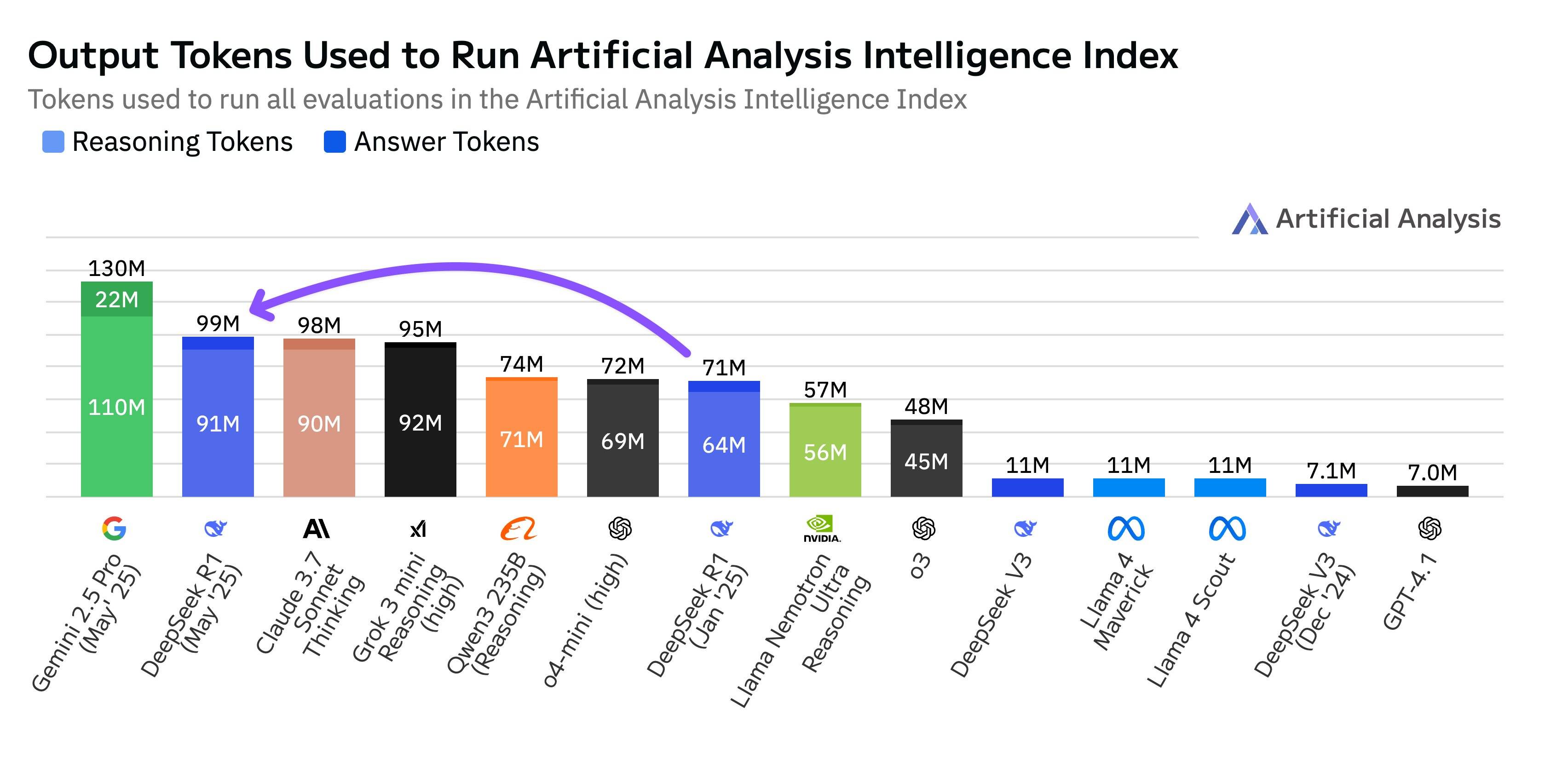
Artificial Analysis还透露,DeepSeek-R1-0528在完成该项评估时使用了9900万tokens,比最初R1的7100万tokens多出40%,即新版模型思考时间更长。“但这不是我们见过的最高token使用量,Gemini 2.5 Pro的token使用量比R1-0528还多出30%。”
不少网友在实测中也感受到该模型的思维链变得更长,推理思考更有深度,部分复杂任务甚至耗时可达30分钟至60分钟,这也引发了其过度思考的质疑。
“希望可以控制思考程度,不然实用性有点低,在各种场景里用起来挺麻烦。”有开发者提到。
该机构还认为,DeepSeek-R1-0528的进步带来了三个重要启示。一是开源与闭源模型的差距缩小,开源模型一直保持着与专有模型相当的智能提升。
二是这反映出中美之间AI竞争激烈,中国AI实验室的模型几乎完全赶上了美国同行,这一模型的发布延续了这一趋势。
三是强化学习推动改进,DeepSeek在保持原有架构和预训练的情况下,通过强化学习技术实现了显著的智能提升。
OpenAI此前披露,o1到o3的强化学习计算量增加了10倍,而DeepSeek已经证明他们能够跟上OpenAI的强化学习的计算量增长。
“与预训练相比,扩大强化学习的规模所需的计算量更少,这是一种实现智能提升的高效方式,对于计算资源较少的AI实验室来说尤其有价值。”
后训练推理和高质量数据共同发力,R2还有多远?
很大程度来说,R1新模型的改进很大程度仍归功于DeepSeek在后训练上的进一步优化。
根据DeepSeek的说法,DeepSeek-R1-0528是以2024年12月所发布的DeepSeek V3 Base模型作为基座,通过在后训练过程中投入更多算力和引入算法优化机制,从而显著提升了模型的思维深度与推理能力。
此前,DeepSeek创始人梁文锋署名的团队发布了新论文,以DeepSeek-V3为代表,深入解读了DeepSeek在硬件架构和模型设计方面的关键创新,包括内存优化、算力优化、通信优化和算力加速,从而为实现具有成本效益的大规模训练和推理提供了思路。
有AI从业者表示,DeepSeek-R1-0528此次依然是基于原来的V3的基模进行训练,但性能提升明显,而且蒸馏的小模型还能打败更大模型,证明了后训练的无限潜力。
“强化学习是一种提高AI性能的强大技术,它的计算成本也很高。但Deepseek在强化学习驱动的改进方面的成功表明,扩展强化学习可能比扩展预训练更有效。”
国内头部大模型核心算法研究员AI Dance还对搜狐科技提到,此次R1新模型改进比较明显的是代码能力,还离不开高质量的数据。
“DeepSeek-R1-0528成功的范式,关键在于更多更高质量的后训练数据,而不是迷信推理模式。这不意味着强化学习推理完全没用,二者不是非此即彼,而是迭代提升。推理模式提供思考框架,高质量数据提供了具体的知识和经验,两者结合才能达到最好效果。”
该人士认为,现在大家都在卷推理,但忽略了数据质量这个更朴素的东西。DeepSeek-R1-0528此次给大家也提了个醒,即高质量的后训练数据的边际收益很高。
两个月前,DeepSeek宣布V3模型更新升级到DeepSeek-V3-0324,其在编程能力、数学推理、创造性任务等方面进一步优化,当时被评为全球“最强非推理模型”。
此次随着R1模型也迎来更新,再次引发网友对R2的关注。“这不是个小升级,现在看来暂时不会看到R2”,前述研究员也预测可能要等V4发布后才会有R2。
目前在社区平台有不少关于R2的消息流出,包括参数规模将翻倍提升到1.2万亿,成本将大幅下降,预计今年第三季度推出。不过,这些消息未得到DeepSeek官方证实。

DeepSeek方面最新在用户群中表示,目前暂不对外进行项目合作,不提供私有化部署及相关支持服务,并表示“将集中研发精力奉上更强的模型,敬请期待”。这意味着DeepSeek依然不考虑商业化,而是专注研发。
网友们也似乎总结出DeepSeek的发布规律:逢重要节假日前更新。下一个重要节假日是重合在一起的中秋和国庆,看看届时DeepSeek又会放出什么大招吧。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏





